
1. 판다스(pandas) : 정형데이터를 다룰 때 편리한 파이썬 패키지
- csv 파일 형태(c : 콤마)로 콤마로 데이터 구분이 된 데이터를 읽어올 수 있음
- 판다스로 csv파일을 불러오면 DataFrame 형태로 예쁘게 불러올 수 있고, range index가 0부터 붙여지게됨.
- 즉, 판다스는 DataFrame 형태로 데이터를 읽어서 핸들링할 수 있는 패키지
2. 라이브러리 및 csv파일 불러와서 변수에 저장하기
ㅇ import pandas as pd
ㅇ df = pd.read_csv('파일명.csv')
ㅇ df.head() / df.tail()
# 판다스 라이브러리 불러오기
import pandas as pd
# 데이터 불러와서 변수에 담기
df = pd.read_csv('ㅇㅇㅇ.csv')
# 데이터 샘플 확인하기
df.head() # 앞에서부터 n개 확인(기본 5개)
df.tail(n) # 뒤에서부터 n개 확인(기본 5개)3. 데이터 프레임과 시리즈
ㅇ 시리즈 만들기 : pd.Series([ㅇㅇ, ㅇㅇ, ㅇㅇ])
ㅇ 데이터프레임 만들기 : pd.DataFrame({"컬럼명":데이터})
ㅇ 시리즈 선택 : df['컬럼명']
ㅇ 데이터프레임 선택 : df[['컬럼1', '컬럼2']]
ㅇ 시리즈 유형 확인 : type(df['컬럼명'])
ㅇ 데이터프레임 유형 확인 : type(df)


4. EDA(탐색적 데이터 분석)
ㅇ 데이터 프레임 크기(행,열 개수) 확인 : df.shape
ㅇ 컬럼 형태 확인 : df.info()
ㅇ 컬럼명 출력 : df.columns
- N번째 컬럼 출력 : df.columns[N-1] # index가 0부터 시작하므로
- N번째 컬럼 유형 확인 : df.iloc[:N-1].dtype
ㅇ 인덱스 구성 : df.index
ㅇ 수치형 변수를 가진 컬럼 출력 : df.select_dtypes(exclude = object).columns
ㅇ 범주형 변수를 가진 컬럼 출력 : df.select_dtypes(include = object).coumns
ㅇ A 텍스트 포함/불포함 여부 확인
- df.컬럼명.str.contains('A')
- ~df.컬럼명.str.contains('A')
ㅇ N 숫자 포함 여부
list = [숫자 리스트]
df.loc[df.컬럼.isin(list)]
ㅇ A로 시작하는 데이터 : df.컬럼명.str.startswith('A')
ㅇ 기초통계(최소, 표준편차, 중앙값 등) 확인 : df.describe() / df.describe(includ='0') #범주형 데이터도 확인 가능
ㅇ 상관관계 분석 : df.corr()
ㅇ 데이터 항목 종류 확인
- 컬럼별 종류 수 : 변수명.nunique()
- 컬럼별 항목 종류 : 변수명['컬럼명'].unique()
ㅇ 빈도수 : .value_counts
ㅇ 소수점 자리수(반올림) : round(df['변수명'], 자릿수(0,1,2...))

5. 자료형 변환
ㅇ 데이터프레임 자료형 변환 : df['컬럼명'] = df['컬럼명'].astype('변환할 자료형')

6. 데이터 삭제 : drop
ㅇ df = df.drop('컬럼명', 행(0)/열(1) 방향)
ㅇ 결측치 데이터 행 삭제 : df.dropna()
ㅇ 특정 컬럼에 결측치가 있는 경우 행 삭제 : df.dropna(subset=['컬럼명'])
ㅇ 중복데이터 삭제
- 첫번쨰 데이터 남기기 : df.drop_duplicates('컬럼명')
- 마지막 데이터 남기기 : df.drop_duplicates('컬럼명', keep='last')
7. csv 저장하기 : to_csv
ㅇ df.to_csv('파일명.csv', index=False) # index = False 미포함 시 index번호도 데이터로 인식해서 저장하게 됨


8. 인덱싱/슬라이싱
ㅇ 데이터프레임에서 특정 행 선택
- loc[인덱스 명]
- iloc[인덱스 번호]
ㅇ 데이터프레임에서 특정 열 선택
- loc[인덱스 명, 컬럼명]
- iloc[인덱스 번호, 컬럼 번호] # 인덱스 번호로 기재되는 번호 데이터는 포함하지 않고 출력됨
# 범위가 될 수도 있기 때문에 a:b // 전체 데이터 선택 시 :
ㅇ 짝수번째 컬럼만 포함하는 데이터프레임 : df.iloc[:,:,2]
ㅇ 한 셀의 데이터 중 a:b번째 text까지 선택 : str[a:b]


9. 데이터 추가
ㅇ 결측값 추가 : numpy 활용
import numpy as np
df['추가할 컬럼명'] = np.nan
ㅇ 데이터 추가
df.loc[인덱스 명, '추가할 컬럼명'] = 추가할 데이터
ㅇ 리스트[] 형태로 추가 : 컬럼 개수만큼 데이터 추가 필요
df.loc[인덱스 명] = [a,b,c,d]
ㅇ 딕셔터리{} 형태로 추가 : 컬럼 개수만큼 데이터 추가 불요하며, 추가할 데이터가 없는 키값은 결측치(NaN)으로 채움
df.loc[인덱스 명] = {컬럼1:a, 컬럼2:b, 컬럼3:c}
10. 데이터정렬(sort)
* 정렬 전에 데이터유형(정수/문자 등)은 동일하게 맞춰야함 : drop을 이용해서 데이터 삭제
ㅇ 인덱스 기준(기본값 ascending=True) : sort_index(ascending = True 오름차순 / False 내림차순)
ㅇ 값 기준(기본값 ascending=True) : sort_values('컬럼명', ascending = True / Flase)
ㅇ 복수 컬럼 값 기준 정렬 : sort_values(['컬럼1', '컬럼2'], ascending = [True/False, Ture/Flase])
ㅇ 정렬한 df 기준으로 새로운 index 만들기 : reset_index(drop=True)



11. 조건필터
ㅇ 기준이 하나 일 때
cond = df["컬럼명'] >=20
df[cond]
ㅇ 기준이 둘 이상 일 때
cond1 = df['컬럼명' > = 20
cond2 = df['컬럼명'] == a
df[cond1 & cond2] # and
df[cond1 | cond2] # or



12. 결측값(NaN)
ㅇ 결측치 확인 : df.isnull().sum()
ㅇ 결측값 채우기 : df['컬럼명'].fillna(데이터)

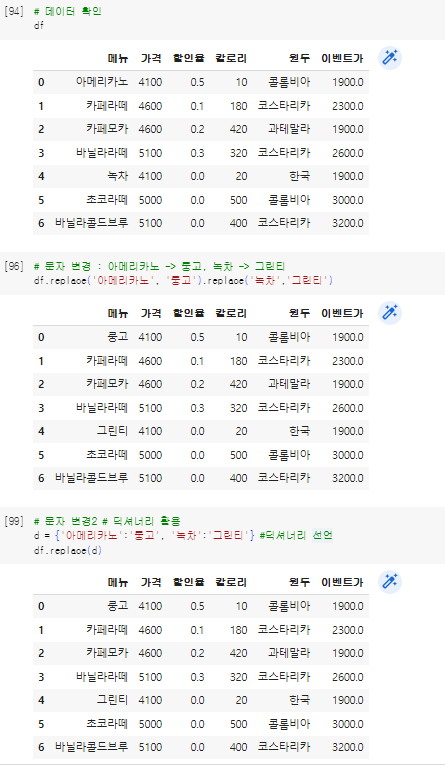
13. 데이터변경
ㅇ replace(변경대상데이터, 변경할데이터)
ㅇ 딕셔너리 선언 후, replace(딕셔너리 변수명)
ㅇ loc로 데이터 선택 후 변경
ㅇ 행/열 데이터 바꾸기 : df.T

14. 내장함수
ㅇ 결측치 제외 컬럼/행 별 데이터 개수 카운트 : count(axis = 0(열)/1(행))
ㅇ 데이터 개수 : len(df) / df.shape[0]
ㅇ 최대값 : df['컬럼명'].max()
ㅇ 최소값 : df['컬럼명'].min()
ㅇ 평균 : df['컬럼명'].mean()
ㅇ 중앙값 : df['컬럼명'].median()
ㅇ 합계 : df['컬럼명'].sum()
ㅇ 표준편차 : df['컬럼명'].std()
ㅇ 분산 : df['컬럼명'].var()
ㅇ 왜도 : df['컬럼명'].skew()
ㅇ 첨도 : df['컬럼명'].kurt()
ㅇ 백분위수 : df['컬럼명'].describe()
ㅇ 백분위수 값 : df['컬럼명'].quantile(.25)
ㅇ 최빈값 : df['컬럼명'].mode()[0]



15. 기타함수
ㅇ apply : 함수를 만들어서 적용

ㅇ 그룹핑 : groupby('컬럼')
- 데이터프레임 형태로 출력 : df.groupby([컬럼1,컬럼2], as_index = False)
- 컬럼별 빈도수 : df.groupby(컬럼명).size()
* df.컬럼명.value_counts().sort_index()
- 연산 : .agg(['mean', 'var', 'max', 'min'])


2023.05.07 - [자격증공부/빅데이터분석기사] - [빅데이터분석기사] 빅데이터분석기사 시험정보
[빅데이터분석기사] 빅데이터분석기사 시험정보
[자격증 소개] ㅇ 소개 : 빅데이터 이해를 기반으로 빅데이터 분석기획, 빅데이터 수집/저장/처리, 빅데이터 분석 및 시각화를 수행하는 실무자를 빅데이터분석기사라고 정의한다. ㅇ 주관 : 한
inform.workhyo.com
2023.06.12 - [자격증공부/빅데이터분석기사] - [빅데이터분석기사][작업형1] 판다스 문법 활용 요약
[빅데이터분석기사][작업형1] 판다스 문법 활용 요약
1. 라이브러리 및 데이터 읽어오기 ㅇ 컬럼명 확인할 수 있도록 세팅하기 import pandas as pd df = pd.read_csv('ㅇㅇㅇㅇ.csv') pd.set_option('display.max_columns', None) #컬럼명 전부 확인할 수 있도록 셋팅하기 2.
inform.workhyo.com
'자격증공부 > 빅데이터분석기사' 카테고리의 다른 글
| [빅데이터분석기사] 작업형1 기출문제 3회 (기초통계, 결측치) (0) | 2023.05.22 |
|---|---|
| [빅데이터분석기사] 작업형1 기출문제 2회 (이상치, 기초통계) (0) | 2023.05.21 |
| [빅데이터분석기사] 작업형1 예시문제 Min-Max Scale (0) | 2023.05.20 |
| [빅데이터분석기사] 데이터분석을 위한 파이썬 학습 (0) | 2023.05.15 |
| [빅데이터분석기사] 빅데이터분석기사 시험정보 (0) | 2023.05.07 |



