320x100

* 인프런의 '퇴근후딴짓' 님의 강의를 참고하였습니다.*
[문제1] 결측치 데이터(행)을 제거하고, 앞에서부터 70% 데이터만 활용해 'f1' 컬럼 1사분위 값을 구하시오.
# 라이브러리 및 데이터 읽기
# 결측치 데이터(행) 제거 : dropna()
# 70% 데이터 활용
# f1 컬럼의 1사분위 값 구하기
# 라이브러리 및 데이터 읽기
import pandas as pd
df = pd.read_csv('member.csv')
# 결측치 데이터(행) 제거 : dropna()
# print(df.isnull().sum())
# print(df.shape)
df = df.dropna()
# print(df.isnull().sum())
# print(df.shape)
# 70% 데이터 활용
# print(int(len(df)*0.7))
df = df.iloc[:int(len(df)*0.7)]
# print(df.shape)
# f1 컬럼의 1사분위 값 구하기
print(df['f1'].quantile(.25))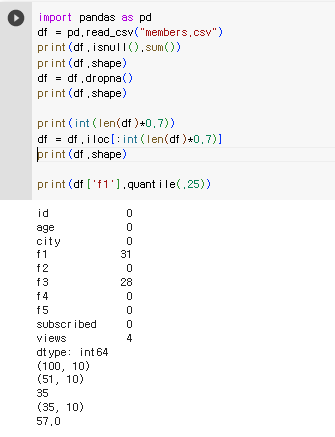
320x100
[문제2] index는 년도임. 2000년 데이터 중 2000년 평균보다 큰 값의 데이터 수
# 라이브러리 및 데이터 읽기
# 2000년도 데이터 선택
# 2000년도 평균 및 평균보다 큰 값 데이터 수 구하기
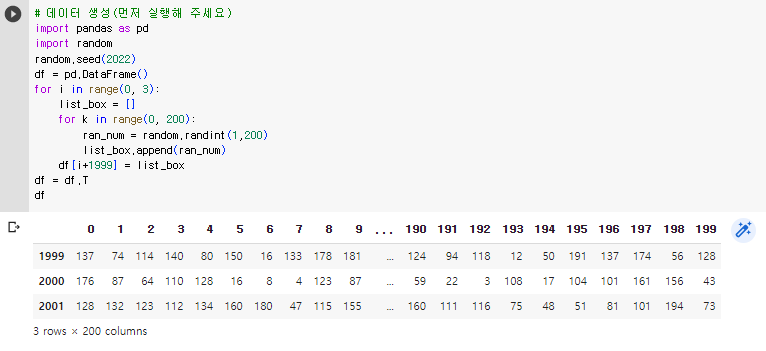
# 방법1
m = df.loc[2000].mean()
print(sum(df.loc[2000,:] > m))
# 방법2
df = df.T
m = df[2000].mean()
print(sum(df[2000] > m))반응형
[문제3] 결측치가 제일 큰 값의 컬럼명
# 라이브러리 및 데이터 읽기
# 결측치 확인
# 결측치 컬럼 명 읽기
import pandas as pd
df = pd.read_csv("members.csv")
# 방법1
# df = df.isnull().sum()
# df = df.sort_values(ascending=False)
# print(df.index[0])
# 방법2
df = df.isnull().sum()
df = df.reset_index()
print(df.loc[3, 'index'])
2023.06.12 - [자격증공부/빅데이터분석기사] - [빅데이터분석기사][작업형1] 판다스 문법 활용 요약
[빅데이터분석기사][작업형1] 판다스 문법 활용 요약
1. 라이브러리 및 데이터 읽어오기 ㅇ 컬럼명 확인할 수 있도록 세팅하기 import pandas as pd df = pd.read_csv('ㅇㅇㅇㅇ.csv') pd.set_option('display.max_columns', None) #컬럼명 전부 확인할 수 있도록 셋팅하기 2.
inform.workhyo.com
320x100
반응형
'자격증공부 > 빅데이터분석기사' 카테고리의 다른 글
| [빅데이터분석기사] 작업형1 문제유형 (이상치, 기초통계) (0) | 2023.05.24 |
|---|---|
| [빅데이터분석기사] 작업형1 문제유형 (결측치) (0) | 2023.05.23 |
| [빅데이터분석기사] 작업형1 기출문제 2회 (이상치, 기초통계) (0) | 2023.05.21 |
| [빅데이터분석기사] 작업형1 예시문제 Min-Max Scale (0) | 2023.05.20 |
| [빅데이터분석기사] 데이터핸들링을 위한 판다스 학습 - 작업형1 (0) | 2023.05.18 |



