
* 퇴근후딴짓 님의 강의를 참고하였습니다. *
[ 문제 ]
제품 배송시간에 맞춰 배송되었는지 예측모델 만들기
학습용 데이터 (X_train, y_train)을 이용하여 배송 예측 모형을 만든 후, 이를 평가용 데이터(X_test)에 적용하여 얻은 예측(시간에 맞춰 도착하지 않을 확률)값을 다음과 같은 형식의 CSV파일로 생성하시오(제출한 모델의 성능은 ROC-AUC 평가지표에 따라 채점)
ㅇ 제공 데이터 : X_train.csv, y_train.csv, X_test.csv
ㅇ 0 정시도착, 1 정시도착하지 않음
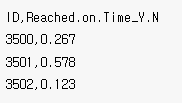
[ 풀이 ]
1. 라이브러리, 데이터 불러오기
# 데이터 불러오기
import pandas as pd
X_test = pd.read_csv("X_test.csv")
X_train = pd.read_csv("X_train.csv")
y_train = pd.read_csv("y_train.csv")
X_train.shape, y_train.shape, X_test.shape
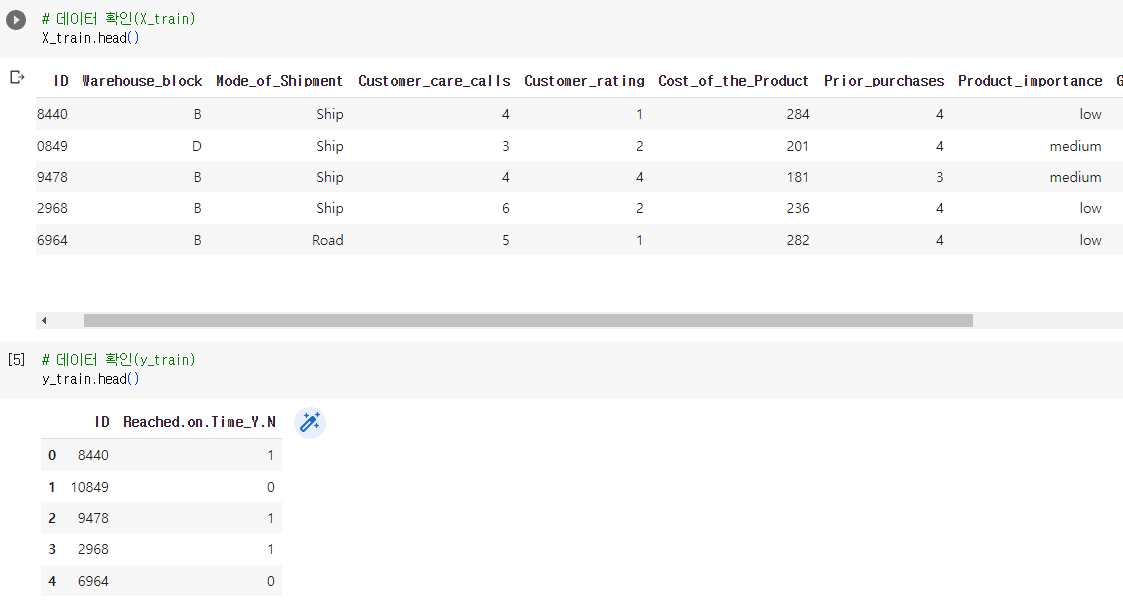
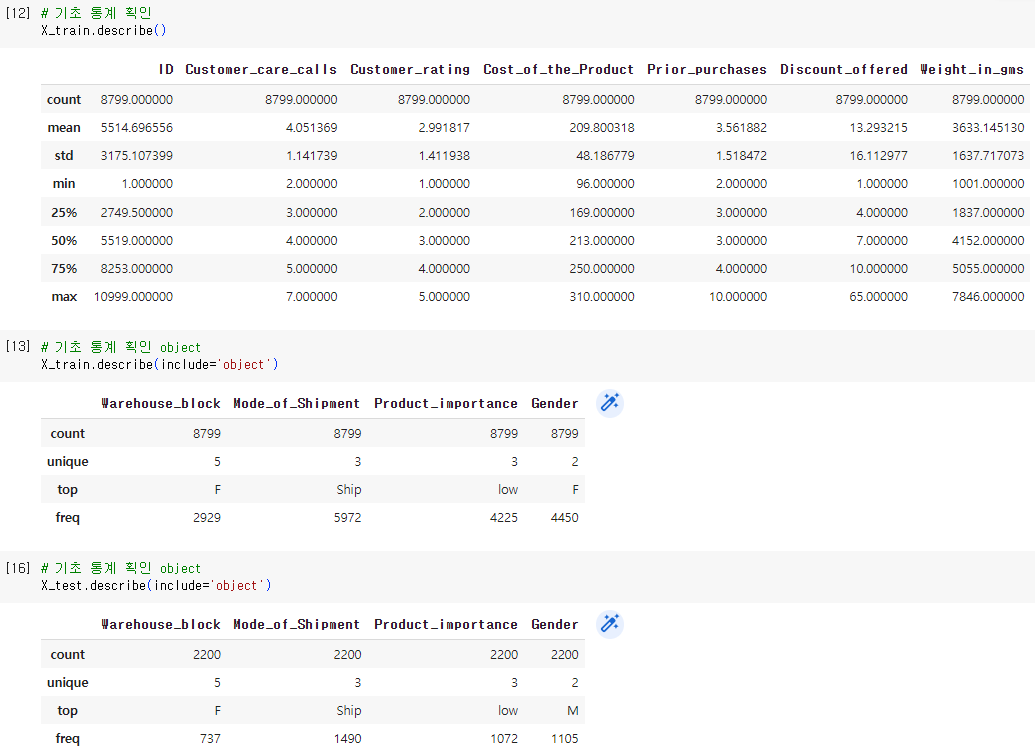
2. EDA : 데이터확인, shape, 결측치확인(isnull().sum()), 타겟레이블 비율 확인(y_train['컬럼'].value_counts()), 데이터타입확인(info()), 기초통계확인(decribe() / describe(include='object')),

3. 데이터전처리 및 피처엔지니어링
ㅇ 이상치/결측치 처리 : 처리할 결측치 없음
ㅇ 범주형 데이터는 수치형으로 변환 : 라벨인코딩 / 원핫인코딩
ㅇ X_train에서 ID값 삭제 : drop, X_test의 출력할 ID값 옮겨두기 : pop
# 라벨 인코딩
from sklearn.preprocessing import LabelEncoder
cols = X_train.select_dtypes(include='object').columns
# print(cols)
for col in cols:
le = LabelEncoder()
X_train[col] = le.fit_transform(X_train[col])
X_test[col] = le.transform(X_test[col])
X_train.head()
# trainID 삭제, testID 값만 옮겨둠
X_train = X_train.drop('ID', axis=1)
X_test_id = X_test.pop('ID')
4. 모델 및 평가
ㅇ 모델 라이브러리 불러오기
ㅇ 검증 데이터 분리 : X_tr, X_val, y_tr, y_val
# 라이브러리 불러오기
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
from sklearn.metrics import roc_auc_score
# 검증 데이터 분리
from sklearn.model_selection import train_test_split
X_tr, X_val, y_tr, y_val = train_test_split(
X_train,
y_train['Reached.on.Time_Y.N'], #타겟컬럼만 선정
test_size=0.2, #검증용 데이터는 0.2정도 가져가겠다
random_state=2021 #매번 실행할 때마다 동일하게 분리하기 위해 값 필요
)
X_tr.shape, X_val.shape, y_tr.shape, y_val.shapeㅇ X_tr, y_tr로 모델 학습시키고, X_val 데이터로 예측하고, y_val로 타겟컬럼 평가하기
# 로지스틱 회귀
model = LogisticRegression(random_state=2022)
model.fit(X_tr, y_tr) # 학습
pred = model.predict_proba(X_val) # 확률 예측
print(roc_auc_score(y_val, pred[:,1])) #y_val로 타켓컬럼 정확도 예측
# 의사결정나무
model = DecisionTreeClassifier(random_state=2022)
model.fit(X_tr, y_tr)
pred = model.predict_proba(X_val)
print(roc_auc_score(y_val, pred[:,1]))
# 랜덤포레스트
model = RandomForestClassifier(random_state=2022)
model.fit(X_tr, y_tr)
pred = model.predict_proba(X_val)
print(roc_auc_score(y_val, pred[:,1]))
# XGBOOST
model = XGBClassifier(random_state=2022)
model.fit(X_tr, y_tr)
pred = model.predict_proba(X_val)
print(roc_auc_score(y_val, pred[:,1]))

5. 예측 및 제출
ㅇ 위 모델 중 가장 높은 확률을 가진 모델로 X_test 데이터로 예측
ㅇ 제출할 데이터프레임 만들고, 데이터 확인
ㅇ CSV파일 만들기
ㅇ 제대로 제출되었는지 확인
# 예측 (test데이터로 예측)
pred = model.predict_proba(X_test)
pred
# 데이터프레임 만들기
submit = pd.DataFrame({
"ID" : X_test_id,
"Reached.on.Time_Y.N" : pred[:,1]
})
# 데이터 확인
submit.head()
# CSV파일 만들기
submit.to_csv('00000000.csv', index=False)
pd.read_csv('00000000.csv')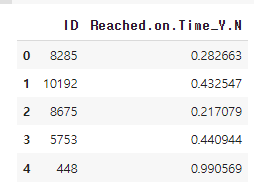
2023.06.12 - [자격증공부/빅데이터분석기사] - [빅데이터분석기사][작업형1] 판다스 문법 활용 요약
[빅데이터분석기사][작업형1] 판다스 문법 활용 요약
1. 라이브러리 및 데이터 읽어오기 ㅇ 컬럼명 확인할 수 있도록 세팅하기 import pandas as pd df = pd.read_csv('ㅇㅇㅇㅇ.csv') pd.set_option('display.max_columns', None) #컬럼명 전부 확인할 수 있도록 셋팅하기 2.
inform.workhyo.com
2023.06.12 - [자격증공부/빅데이터분석기사] - [빅데이터분석기사][작업형2] 머신러닝 이론 및 프로세스 요약
[빅데이터분석기사][작업형2] 머신러닝 이론 및 프로세스 요약
* 퇴근후딴짓 님의 강의를 참고하였습니다. * 1. 머신러닝 ㅇ기존에는 데이터/규칙을 Rule Base로 결과를 도출하였지만, 머신러닝은 데이터와 결과(해답)을 기반으로 학습을 통해 규칙을 도출하고
inform.workhyo.com
'자격증공부 > 빅데이터분석기사' 카테고리의 다른 글
| [빅데이터분석기사] 작업형2 문제유형 (분류) (0) | 2023.06.12 |
|---|---|
| [빅데이터분석기사] 작업형2 기출문제 3회 (분류) (0) | 2023.06.11 |
| [빅데이터분석기사] 작업형2 예시문제 (분류) (0) | 2023.06.09 |
| [빅데이터분석기사] 실기시험 응시환경 및 Tip (0) | 2023.06.08 |
| [빅데이터분석기사] 작업형1 문제유형 (기초통계, 그룹통계, 날짜) (0) | 2023.06.07 |



