
* 퇴근후딴짓 님의 강의를 참고하였습니다. *
[ 문제 ]
신용카드서비스를 떠나는 고객 찾기
ㅇ 데이터 : trian.csv, test.csv
ㅇ 나이, 급여, 결혼상태, 신용카드한도 등의 컬럼이 있음
ㅇ 평가 : ROC_AUC, 정확도(Accuracy), F1, 정밀도(Precision), 재현율(Recall) 구하기
ㅇ 타겟데이터 : Attrition_Flag(1:이탈, 0:유지)
[ 풀이 ]
1. 라이브리러, 데이터 불러오기
import pandas as pd
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
2. EDA
print(train.shape, test.shape)
print(train.head(), test.head())
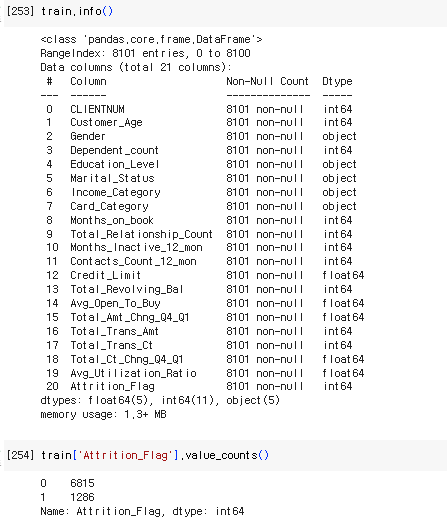
train.info()
train['Attrition_Flag'].value_counts()
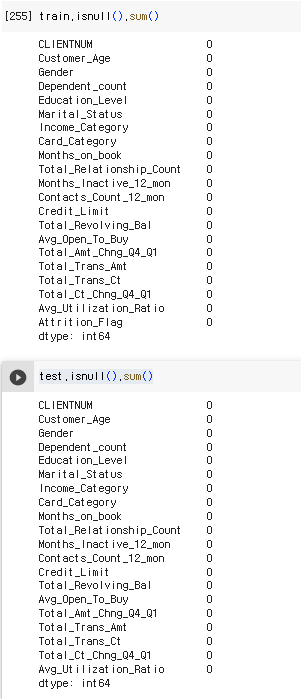
train.isnull().sum()
test.isnull().sum()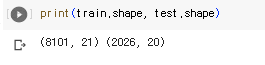
3. 데이터 전처리 & 피처엔지니어링
ㅇ 범주형 데이터 - baseline(제거) / 라벨인코딩 / 원핫인코딩
cols = train.select_dtypes(include='object').columns
cols
# baseline : object 컬럼 제거'
# print(train.shape, test.shape)
# train = train.drop(cols, axis=1)
# test = test.drop(cols, axis=1)
# print(train.shape, test.shape)
# train = train.drop(cols, axis=1, inplace=True) 위와 동일한 결과로 바로 적용됨
# 범주 label : 컬럼 1개씩 해야함
from sklearn.preprocessing import LabelEncoder
for col in cols:
le = LabelEncoder()
train[col] = le.fit_transform(train[col])
test[col] = le.transform(test[col])
train[cols].head()
# 범주 one-hot 인코딩
# train = pd.get_dummies(train, columns=cols)
# test = pd.get_dummies(test, columns=cols)ㅇ train 데이터에서 CLIENTNUM 컬럼 drop, test데이터에서 CLIENTNUM 컬럼 test_id로 저장하고 pop
train = train.drop('CLIENTNUM', axis=1)
test_id = test.pop('CLIENTNUM')
train.head(), test_id
4. 검증데이터 분리
# 검증데이터 분리
from sklearn.model_selection import train_test_split
X_tr, X_val, y_tr, y_val = train_test_split(
train.drop('Attrition_Flag', axis=1), train['Attrition_Flag'], test_size=0.2, random_state=2022)
X_tr.shape, X_val.shape, y_tr.shape, y_val.shape
# 타겟컬럼을 제외한 train 데이터, train데이터의 taget컬럼, testsize, 동일한 값5. 모델 & 검증데이터로 평가
# 모델 불러오기, fit 학습하고, predict 예측
# 랜덤포레스트
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(random_state=2022)
model.fit(X_tr, y_tr)
pred = model.predict(X_val)
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
# 정확도
print(accuracy_score(y_val, pred))
# 정밀도
print(precision_score(y_val, pred))
# 재현율 (민감도)
print(recall_score(y_val, pred))
# F1
print(f1_score(y_val, pred))
# 베이스라인 기준
0.9666872301048736
0.9444444444444444
0.8435114503816794
0.8911290322580645
0.8752556237218814
# 레이블인코딩
0.9685379395434917
0.948936170212766
0.851145038167939
0.89738430583501
0.8752556237218814
# 원핫인코딩
0.9605181986428131
0.9419642857142857
0.8053435114503816
0.868312757201646
0.8752556237218814
# roc-auc
pred = model.predict_proba(X_val) # 0일때 확률, 1일때 확률 2개값 반환
print(roc_auc_score(y_val, pred[:,1])) #1일때 확률
# 베이스라인 기준
0.9904243128928434
# 레이블인코딩
0.9904243128928434
# 원핫인코딩
0.9904243128928434
6. 예측 및 저장
pred = model.predict_proba(test)
pred
submit = pd.DataFrame({
'CLIENTNUM':test_id,
'Attrition_Flag':pred[:,1]
})
submit.to_csv('0000.csv', index=False)
# pd.read_csv('0000.csv')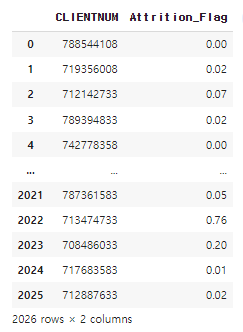
2023.06.12 - [자격증공부/빅데이터분석기사] - [빅데이터분석기사][작업형2] 머신러닝 이론 및 프로세스 요약
[빅데이터분석기사][작업형2] 머신러닝 이론 및 프로세스 요약
* 퇴근후딴짓 님의 강의를 참고하였습니다. * 1. 머신러닝 ㅇ기존에는 데이터/규칙을 Rule Base로 결과를 도출하였지만, 머신러닝은 데이터와 결과(해답)을 기반으로 학습을 통해 규칙을 도출하고
inform.workhyo.com
2023.06.12 - [자격증공부/빅데이터분석기사] - [빅데이터분석기사][작업형1] 판다스 문법 활용 요약
[빅데이터분석기사][작업형1] 판다스 문법 활용 요약
1. 라이브러리 및 데이터 읽어오기 ㅇ 컬럼명 확인할 수 있도록 세팅하기 import pandas as pd df = pd.read_csv('ㅇㅇㅇㅇ.csv') pd.set_option('display.max_columns', None) #컬럼명 전부 확인할 수 있도록 셋팅하기 2.
inform.workhyo.com
'자격증공부 > 빅데이터분석기사' 카테고리의 다른 글
| [빅데이터분석기사] 작업형1 판다스 문법 활용 요약 (0) | 2023.06.12 |
|---|---|
| [빅데이터분석기사] 작업형2 머신러닝 이론 및 프로세스 요약 (0) | 2023.06.12 |
| [빅데이터분석기사] 작업형2 기출문제 3회 (분류) (0) | 2023.06.11 |
| [빅데이터분석기사] 작업형2 기출문제 2회 (분류) (0) | 2023.06.10 |
| [빅데이터분석기사] 작업형2 예시문제 (분류) (0) | 2023.06.09 |



