
* 퇴근후딴짓 님의 강의를 참고하였습니다. *
[ 문제 ]
에어비앤비 가격
ㅇ 데이터 : train.csv, test.csv
ㅇ 타겟 : price(가격)

[ 풀이 ]
1. 라이브러리 및 데이터 불러오기
import pandas as pd
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
print(train.shape, test.shape)
2. EDA
train.head(3)
test.head(2)
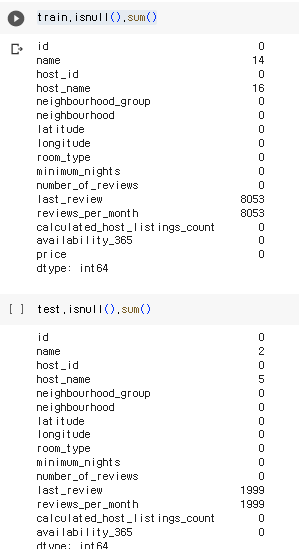
train.isnull().sum()
test.isnull().sum()
train['price'].describe() #그림을 그릴 수 없어서 대략적인 분포 확인
train.info()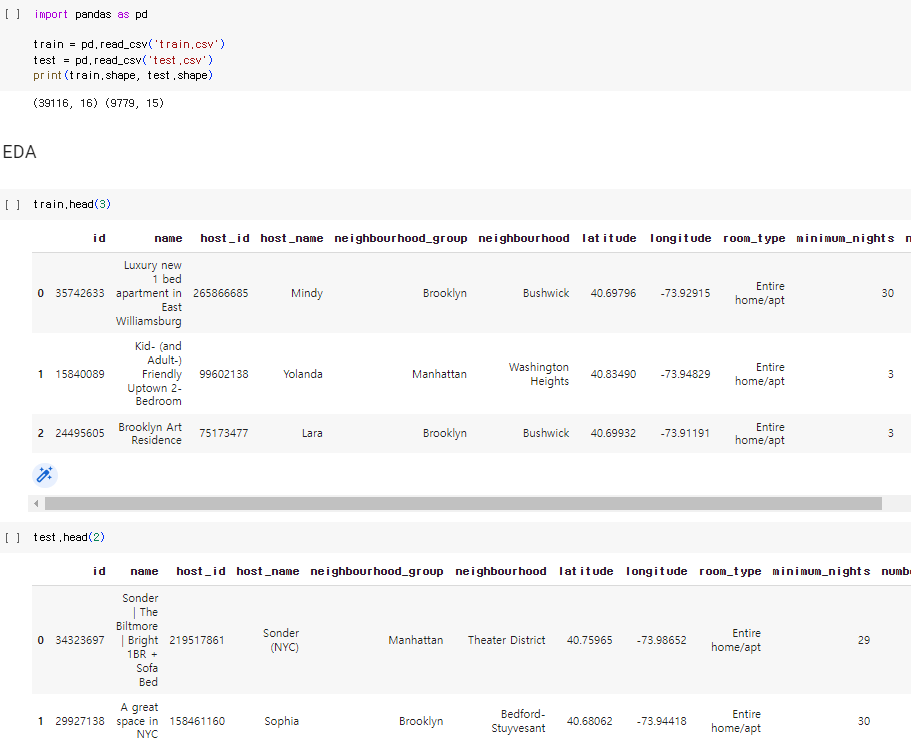
3. 데이터전처리 및 피처엔지니어링
ㅇ 결측치 처리
train.nunique()
# name, host_name, last_review, host_id 삭제, reviews_per_month 0으로 채우기
cols = ['name', 'host_name', 'last_review', 'host_id']
print(train.shape)
train = train.drop(cols, axis=1)
test = test.drop(cols, axis=1)
print(train.shape)
train['reviews_per_month'] = train['reviews_per_month'].fillna(0)
test['reviews_per_month'] = test['reviews_per_month'].fillna(0)
train.isnull().sum()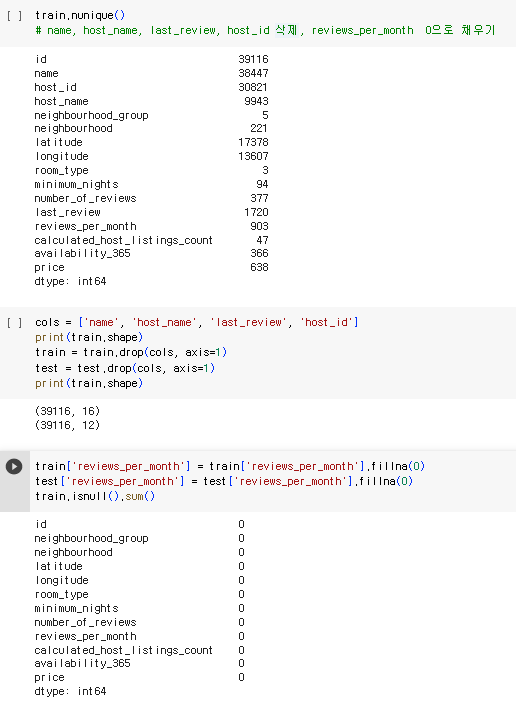
ㅇ train에서 id값 삭제, test_id 남기기
train = train.drop('id',axis=1)
test_id = test.pop('id')
test.head()
ㅇ 범주형 데이터를 수치형으로 만들기(인코딩)
# 레이블 인코딩
cols=['neighbourhood_group', 'neighbourhood', 'room_type']
from sklearn.preprocessing import LabelEncoder
for col in cols:
le = LabelEncoder()
train[col] = le.fit_transform(train[col])
test[col] = le.transform(test[col])
train[cols]
4. 모델&평가(검증 데이터 분리)
ㅇ 검증데이터 분리
from sklearn.model_selection import train_test_split
X_tr, X_val, y_tr, y_val = train_test_split(
train.drop('price', axis=1), train['price'], test_size=0.15, random_state=2022
)
X_tr.shape, X_val.shape, y_tr.shape, y_val.shapeㅇ 평가지표(회귀모델)
# 평가지표(회귀)
# MAE : 실제값과 예측값 차이를 절대값으로 변환해 평균한 것
# MSE : 실제값과 예측값 차이를 제곱해 평균한 것
# RMSE : MSE에 루트를 씌운 것
# R2 Score : 회귀 모델의 설명력
# RMSLE : 예측값이 실제값보다 작을 때 더 큰 패널티 부여
# MAPE : MAE를 퍼센트로 표시
# 평가
import numpy as np
from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_error #sklearn에서 제공하는 것
def rmse(y_test, y_pred): #RMSE
return np.sqrt(mean_squared_error(y_test, y_pred))
def rmsle(y_test, y_pred): #RMSLE
return np.sqrt(np.mean(np.power(np.log1p(y_test) - np.log1p(y_pred), 2)))
def mape(y_test, y_pred): #MAPE
return np.mean(np.abs((y_test - y_pred) / y_test)) * 100
ㅇ 모델
# 선형회귀
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_tr, y_tr)
pred = model.predict(X_val)
print("r2:", r2_score(y_val, pred))
print("MAE:", mean_absolute_error(y_val, pred))
print("MSE:", mean_squared_error(y_val, pred))
print("RMSE:", rmse(y_val, pred))
print("RMSLE:", rmsle(y_val, pred))
print("MAPE:", mape(y_val, pred))
# 릿지(생략)
from sklearn.linear_model import Ridge
model = Ridge()
model.fit(X_tr, y_tr)
pred = model.predict(X_val)
print("r2:", r2_score(y_val, pred))
print("MAE:", mean_absolute_error(y_val, pred))
print("MSE:", mean_squared_error(y_val, pred))
print("RMSE:", rmse(y_val, pred))
print("RMSLE:", rmsle(y_val, pred))
print("MAPE:", mape(y_val, pred))
# 라쏘(생략)
from sklearn.linear_model import Lasso
model = Lasso()
model.fit(X_tr, y_tr)
pred = model.predict(X_val)
print("r2:", r2_score(y_val, pred))
print("MAE:", mean_absolute_error(y_val, pred))
print("MSE:", mean_squared_error(y_val, pred))
print("RMSE:", rmse(y_val, pred))
print("RMSLE:", rmsle(y_val, pred))
print("MAPE:", mape(y_val, pred))
# 랜덤포레스트
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor()
model.fit(X_tr, y_tr)
pred = model.predict(X_val)
print("r2:", r2_score(y_val, pred))
print("MAE:", mean_absolute_error(y_val, pred))
print("MSE:", mean_squared_error(y_val, pred))
print("RMSE:", rmse(y_val, pred))
print("RMSLE:", rmsle(y_val, pred))
print("MAPE:", mape(y_val, pred))
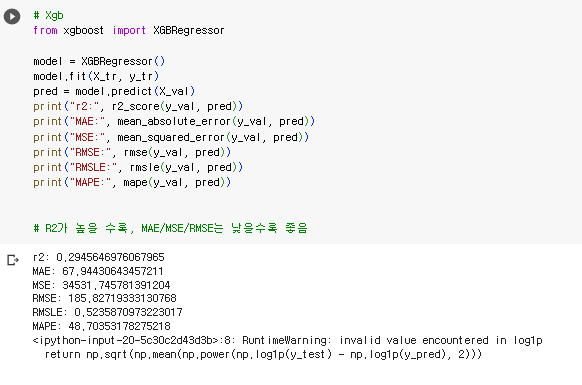
# Xgb
from xgboost import XGBRegressor
model = XGBRegressor()
model.fit(X_tr, y_tr)
pred = model.predict(X_val)
print("r2:", r2_score(y_val, pred))
print("MAE:", mean_absolute_error(y_val, pred))
print("MSE:", mean_squared_error(y_val, pred))
print("RMSE:", rmse(y_val, pred))
print("RMSLE:", rmsle(y_val, pred))
print("MAPE:", mape(y_val, pred))
# R2가 높을 수록, MAE/MSE/RMSE는 낮을수록 좋음

5. 예측 및 CSV제출
pred = model.predict(test)
pd.DataFrame({
'id':test_id,
'output':pred}).to_csv('0000.csv', index=False)
pd.read_csv('0000.csv')
2023.06.12 - [자격증공부/빅데이터분석기사] - [빅데이터분석기사] 작업형1 판다스 문법 활용 요약
[빅데이터분석기사][작업형1] 판다스 문법 활용 요약
1. 라이브러리 및 데이터 읽어오기 ㅇ 컬럼명 확인할 수 있도록 세팅하기 import pandas as pd df = pd.read_csv('ㅇㅇㅇㅇ.csv') pd.set_option('display.max_columns', None) #컬럼명 전부 확인할 수 있도록 셋팅하기 2.
inform.workhyo.com
2023.06.12 - [자격증공부/빅데이터분석기사] - [빅데이터분석기사] 작업형2 머신러닝 이론 및 프로세스 요약
[빅데이터분석기사][작업형2] 머신러닝 이론 및 프로세스 요약
* 퇴근후딴짓 님의 강의를 참고하였습니다. * 1. 머신러닝 ㅇ기존에는 데이터/규칙을 Rule Base로 결과를 도출하였지만, 머신러닝은 데이터와 결과(해답)을 기반으로 학습을 통해 규칙을 도출하고
inform.workhyo.com
'자격증공부 > 빅데이터분석기사' 카테고리의 다른 글
| [빅데이터분석기사][작업형1] 5회 기출문제 풀이(기초통계, 정렬) (0) | 2023.06.17 |
|---|---|
| [빅데이터분석기사] 작업형2 문제유형 (분류) (0) | 2023.06.15 |
| [빅데이터분석기사] 작업형3 가설검정 이론 및 프로세스 (0) | 2023.06.12 |
| [빅데이터분석기사] 작업형1 판다스 문법 활용 요약 (0) | 2023.06.12 |
| [빅데이터분석기사] 작업형2 머신러닝 이론 및 프로세스 요약 (0) | 2023.06.12 |



